
|
|
|
Главная Полное построение алгоритма [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36] [37] [38] [39] [40] [41] [42] [43] [44] [45] [46] [47] [48] [49] [50] [51] [52] [53] [54] [55] [56] [57] [58] [59] [60] [61] [62] [63] [64] [65] [66] [67] [68] [69] [70] [71] [72] [73] [74] [75] [76] [77] [78] [ 79 ] [80] [81] [82] [83] [84] [85] [86] [87] [88] [89] [90] [91] [92] [93] [94] [95] [96] [97] [98] [99] [100] [101] [102] [103] [104] [105] [106] [107] [108] [109] [110] [111] [112] [113] [114] [115] [116] [117] Таким образом, объект i имеет известную вероятность pt выбора и 2рг=1, где суммирование производится по всем объектам. Л1ы должны найти выделенный объект с помощью ряда вопросов типа «да или нет». Разрешается выбрать подмножество объектов и спросить: «принадлежит ли данный объект этому подмножеству?». Некоторый посредник дает правдивый ответ «да» или «нет». Нашей первоочередной задачей будет построение алгоритма, решающего любую задачу поиска в такой форме при минимуме математического ожидания числа вопросов. Заметим, что каждый заданный вопрос делит текущее множество непроверенных объектов на два множества, одно из которых будет проверяться на данном шаге, а другое нет. Например, пусть D - колода из 55 карт, в которой содержится 1 туз, 2 двойки, 3 тройки, .... 9 девяток и 10 десяток. Случайно выбрана карта, и мы должны угадать какая. В рамках общей постановки задачи наше множество состоит из 10 объектов (туз, двойка, тройка, . . ., десятка) с вероятностями Р(туз)=1/55, Р(двойка)=2/55, Р (тройка)=3/55, . . ., P(fe)=fe/55, . . ., Р (десятка)=10/55. Начнем разработку алгоритма с попытки обобщения двоичного поиска. Предположим, что объекты упорядочены по возрастанию значений Pi. Попытаемся разбить множество непроверенных объектов посередине. Если число объектов нечетно, отнесем средний объект к подмножеству с меньшими значениями pi. В данном примере первым вопросом будет, «является ли объект шестеркой или больше?». Этот вопрос и ответ на него делят множество возможных ответов на два множества равной мощности. Предположим, что ответом на вопрос будет «нет». Тогда следующим вопросом будет: «четверка или пятерка?». Дерево решений для этого примера показано на рис. 5.2.6. 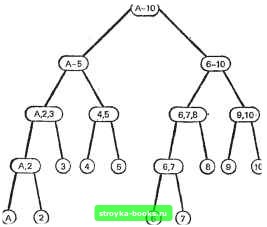 Рис. 5.2.6. Дерево решений для отыскания карты, случайно выбранной из колоды, содержащей тузы, двойки.....десятки. Как же вычислить математическое ожидание числа заданных вопросов при отыскании правильной карты? Числа на самом правом краю рис. 5.2.6 показывают число вопросов, необходимых для достижения вершины на данном уровне при этом алгоритме. Например, если выбранная карта была пятерка, потребуются три вопроса, чтобы убедиться в этом. Математическое ожидание числа задаваемых вопросов при использовании двоичного поиска вычисляется по формуле EQBS= 2 Р (выбран объект i) [NQ(0] = Sp,NQ(i). по всем j объектам где NQ(0 - число вопросов, которые будут заданы, если будет выбран объект t. В нашем примере EQBS=4(l/55)-l-4(2/55)+3 (3/55)-1-3(4/55)-ЬЗ (5/55)4-4 (6/55)+4 (7/55)-}--f 3 (8/55)-Ь3 (9/55)+3 (10/55)-181/55=3.291. Прежде чем смотреть, можно ли разработать лучший алгоритм, сяметим несколько общих соображений. Должно быть очевидно, что любое правило принятия решений можно моделировать двоичным деревом решений (см. разд. 5.1). Каждый вопрос разделяет вершину, представляющую непроверенное множество, на два преемника, представляющих разбиение этого множества. Конечные вершины дерева, т. е. вершины без преемников, представляют одиночные объекты первоначального множества. Внутренние вершины, т. е. те, которые имеют по два преемника, представляют множества из двух или более объектов. Математическое ожидание числа вопросов, которые будут заданы, при любом правиле равно EQ = 2 где суммирование производится по конечным вершинам, ah - длина пути от корня до /-Й конечной вершины. Существует довольно очевидный способ улучшить имеющийся алгоритм двоичного поиска для класса рассматриваемых задач. Попытаемся разбить множество на два подмножества с приблизительно равными вероятностями принадлежности выбранного объекта данному подмножеству. В приведенном примере, если воспользоваться этой модификацией, первьм вопросом был бы: «восьмерка или больше?». Этот вопрос порождает два множества с Р (восьмерка или больше)= -27/55 и Р (семерка или меньше)=28/55. Двоичное дерево для этого алгоритма показано на рис. 5.2.7; для этого дерева EQ=173/55=3.145 (проверьте). Очевидным недостатком этой модификации двоичного поиска является то, что мы вынуждены группировать объекты таким способом, который позволяет нам только выбирать интервалы подряд стоящих объектов при линейном упорядочении. Можно ли получить лучший «вероятноСГНЫй баланс», задавая следующие вопросы: Имеет ли объект нечетный номер? Принадлежит ли объект набору 3, 17, 28, 49? Мы можем воспользоваться этой дополнительной гибкостью, применив весьма простой алгоритм, гарантирующий наилучшее возможное решение этой задачи поиска. 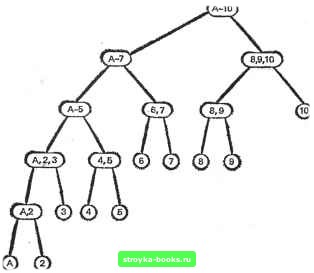 Рис. 5.2.7. Дерево решений для отыскания карты, случайно выбранной из колоды, содержащей тузы, двойки, .... десятки, с разбиением множеств на два подмножества с приблизительно равными вероятностями. Следующая процедура была независимо открыта Хафманом и Циммерманом. Она представляет собой рекурсивный алгоритм, строящий дерево двоичного поиска в обратную сторону, т. е. от конечных вершин к корню. Конечные вершины представляют отдельные объекты и их вероятности, корень представляет множество всех объектов, а внутренние вершины представляют группированные подмножества и их вероятности. Пусть Р„ будет задачей поиска с т>2 объектами, где объект i имеет вероятность pi быть выбранным, и pip2. . -Рт-Основная идея алгоритма состоит в том, чтобы объединить два объекта с наименьшими вероятностями в одно множество и далее решать задачу P„ i с т-1 объектами и вероятностями pi=pi+p2, р2-Рз. •• . . ., рт-г=Рт- Практически дерево поиска в явном виде строится в обратном направлении, как показано на рис. 5.2.8, а для нашего примера. После того как дерево на рис. 5.2.8, а обращено и упорядочено по уровням, мы получаем дерево поиска на рис. 5.2.8, б. Простой подсчет дает EQOST=173/55=3.145. Хотя это значение равно [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36] [37] [38] [39] [40] [41] [42] [43] [44] [45] [46] [47] [48] [49] [50] [51] [52] [53] [54] [55] [56] [57] [58] [59] [60] [61] [62] [63] [64] [65] [66] [67] [68] [69] [70] [71] [72] [73] [74] [75] [76] [77] [78] [ 79 ] [80] [81] [82] [83] [84] [85] [86] [87] [88] [89] [90] [91] [92] [93] [94] [95] [96] [97] [98] [99] [100] [101] [102] [103] [104] [105] [106] [107] [108] [109] [110] [111] [112] [113] [114] [115] [116] [117] 0.0012 |