
|
|
|
Главная Полное построение алгоритма [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36] [37] [38] [39] [40] [41] [42] [43] [44] [45] [46] [47] [48] [49] [50] [51] [52] [53] [54] [55] [56] [57] [58] [59] [60] [61] [62] [63] [64] [65] [66] [67] [68] [69] [70] [71] [72] [73] [74] [75] [76] [77] [ 78 ] [79] [80] [81] [82] [83] [84] [85] [86] [87] [88] [89] [90] [91] [92] [93] [94] [95] [96] [97] [98] [99] [100] [101] [102] [103] [104] [105] [106] [107] [108] [109] [110] [111] [112] [113] [114] [115] [116] [117]
двух преемников. После того как прочитаны первые 9 городов, двоичное дерево приобретает вид, показанный на рис. 5.2.4. Рассмотрим то, что произойдем далее, когда будет прочитан Вашингтон. Так как население Вашингтона больше, чем Энн Арбора, мы переходим к правому преемнику. Затем мы движемся влево от Чикаго, так как в нем больше народу, чем в Вашингтоне. Наконец, мы движемся вправо от Пасадены, так как она меньше Вашингтона. Далее Вашингтон помещается в позицию, отмеченную цифрой 7, и к нему присоединяются фиктивные левый и правый преемники. При дальнейшем изложении мы будем предполагать, что различные записи не могут иметь одинаковых значений ключа; например, у разных городов должны быть разные численности населения. Процедура поиска для этой структуры работает точно так же, как процедура вставления, за исключением того, что процедура поиска успешно завершается, как только мы достигаем вершину со значением ключа, равным ключу поиска. Если достигнута фиктивная вершина, то запись не содержится в дереве, и поиск оказывается безуспешным. Если требуется добавить запись с ключом поиска, ее нужно поместить в дереве вместо достигнутой фиктивной вершины. Algorithm BTSI (Binary Tree Search and Insertion) - (поиск и вставление в двоичном дереве). Нужно найти заданный ключ К в файле с l\Fl записями, организованными в виде двоичного дерева Т. Если К отсутствует, то для него создается новая вершина. К{Р) означает ключ в вершине Р; LEFT(P) и RIGHT (Р) обозначают левого и правого преемников вершины Р. Корневая вершина Т помечена как ROOT; все фиктивные вершины помечены символом Л. Шаг 0. [Инициализация] Set Р ROOT. Шаг 1. [Цикл] While КФК(Р) do шаг 2 od. Шаг 2. [Сравнение и переход] И К<К{Р) then Н LEFT(P)=A then set Рч-ЬВРТ(Р) . else пусть Q обозначает новую вершину; set LEFT (Q) Л; RIGHT(Q) Л; LEFT(P)-t-Q; and STOP fi else if RIGHT(P)=A then set P-RIGHT(P) else пусть Q обозначает новую вершину; set KiQ)<-K; LEFT (Q) Ч- A; RIGHT (Q) <- A; RIGHT (P)Q; and STOP fi fi. Шаг 3. [Успешный поиск] Печать «УСПЕШНОЕ ЗАВЕРШЕНИЕ ПОИСКА»; and STOP. По-видимому, самое худшее, что может сделать алгоритм BTSI, это вести себя, подобно последовательному поиску. К сожалению, это возможно. Это произойдет, если записи считьюаются в дерево упорядоченно. В таком случае двоичное дерево вырождается в простой путь, по существу являющийся линейным списком. Нетрудно видеть, что это наихудший случай. Ann Arbor 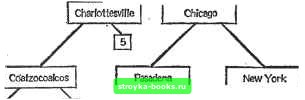 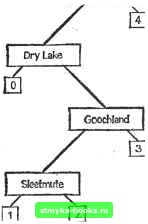 Рис. 5.2.4. Двоичное дерево, упорядоченное по численности нассяения и построенное при чтении первых девяти городов в алфавитном порядке. Chicago Pasadena New York I Charlottesville A как обстоит дело с ожидаемой трудоемкостью алгоритма BTSI? На этот вопрос нелегко ответить. Если дерево полное или почти полное, то алгоритм подобен двоичному поиску и имеет сложность О (logaA). Оказывается, что, если ключи вставляются в случайном порядке, среднее число сравнений по-прежнему равно 0{\og2N). Если считать все двоичные деревья равновероятными, то среднее число сравнений будет 0(УЩ. Доказательства этих утверждений непросты, и их можно найти в книгах [56, 59[. Проблема удаления вершины из двоичного дерева, представляющего упорядоченный файл, несколько сложнее. Не существует никаких затруднений, если оба преемника данной вершины являются фиктивньми (пустыми) вершинами. Например, чтобы удалить Слитмут из дерева на рис. 5.2.4, достаточно просто заменить этот ключ на Л. Чтобы удалить вершину с одним фиктивным преемником - например, Коацакоалькос на рис. 5.2.4,- достаточно просто переместить его левое (или правое) поддерево на место этой вершины. Проблема связей оказывается гораздо сложнее, если у вершины, которую нужно удалить, имеется два непустых преемника. Обычная процедура состоит в следующем: (1) заменить удаляемую вершину ее правым поддеревом RT; (2) сделать левое поддерево удаленной вершины левым поддеревом самой левой вершины RT. На рис. 5.2.5 изображено дерево рис. 5.2.4 после удаления Энн Арбора. В упр. 5.2.10 требуется более явная формулировка алгоритма удаления. Рассмотрим следующую общую задачу поиска. Дано конечное множество объектов. Один из этих объектов предварительно «выделен» в некотором смысле. Мы не знаем выделенного объекта, но известно распределение вероятностей, управлявшее этим выбором. Coatzocoalcos DryLake Goochland Sleetmute Рис. 5.2.5. Двоичное дерево, полученное из дерева на рис. Б.2.4 удалением Энн Арбора, переносом первого поддерева в корень и присоединением левого поддерева ниже Пасадены. [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36] [37] [38] [39] [40] [41] [42] [43] [44] [45] [46] [47] [48] [49] [50] [51] [52] [53] [54] [55] [56] [57] [58] [59] [60] [61] [62] [63] [64] [65] [66] [67] [68] [69] [70] [71] [72] [73] [74] [75] [76] [77] [ 78 ] [79] [80] [81] [82] [83] [84] [85] [86] [87] [88] [89] [90] [91] [92] [93] [94] [95] [96] [97] [98] [99] [100] [101] [102] [103] [104] [105] [106] [107] [108] [109] [110] [111] [112] [113] [114] [115] [116] [117] 0.0012 |