
|
|
|
Главная Полное построение алгоритма [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36] [37] [38] [39] [40] [41] [42] [43] [44] [45] [46] [47] [48] [49] [50] [51] [52] [53] [54] [55] [56] [57] [58] [59] [60] [61] [62] [63] [64] [65] [66] [67] [68] [69] [70] [71] [72] [73] [74] [75] [ 76 ] [77] [78] [79] [80] [81] [82] [83] [84] [85] [86] [87] [88] [89] [90] [91] [92] [93] [94] [95] [96] [97] [98] [99] [100] [101] [102] [103] [104] [105] [106] [107] [108] [109] [110] [111] [112] [113] [114] [115] [116] [117] Полностью постройте алгоритм, основанный на этой идее. L5 1.3. QUICKSORT (реализация). Составьте блок-схему и программу для алгоритма QUICKSORT. 5.1.4. Докажите, что минимальное значение min {ki log ki log fea} достигается при Ai=fea=fe/2. 5.1.5. QUICKSORT (анализ). Покажите, что трудоемкость алгоритма QUICKSORT в худшем случае - порядка 0(N). 5.1.6. Составьте дерево решений, как на рис. 5.1.11, которое показывает, как алгоритм QUICKSORT сортирует ключи в упр. 5.1.1. L5.1.7. Сортировка методом отыскания наименьшего ключа (полное построение). Полностью постройте алгоритм, сортирующий список путем отыскания наименьшего ключа, второго по величине ключа и т. д. до тех пор, пока список не исчерпается и все числа не установятся в возрастающем порядке. *L5.I.8. Слияние (полное построение). Пусть /4=(ci, Сг, . - . , а„), B=(bi, bg, . . .. 6„) и C=(ci, Са, . . . , Ср) - три конечные последовательности действительных чисел, Допустим, что каждая отдельная последовательность упорядочена по возрастанию. Слейте три последовательности в одну последовательность D= [di, dz, . . ., n+m + p}. являющуюся списком всех чисел шз А, В и С (включая построения), такую, что di<C <:Й2<. . .<:dй+я,+,. Разработайте и проанализируйте такой алгоритм. Можете сначала попробовать случай, когда п=т=р. *5.1.9. Сортировка слиянием (разработка, анализ). Разработайте и проанализируйте алгоритм сортировки, работающий с использованием метода слияния (см. упр. 5.1.8). Какие благоприятные возможности вы можете найти для параллельной обработки данных? *5.1.10. Пересечение множеств (разработка, анализ). Пусть у4 и В - два множества неотрицательных целых чисел, в каждом из которых по k элементов. Существует довольно очевидный способ построения множества А{]В с использованием 0(k операций. Применив сортировку, разработайте и проанализируйте алгоритм, находящий Af]B за 0(k\ogk) операций. **L5.1.11. Сравнение методов сортировки (проверка). Рассмотрите все знакомые вам методы сортировки, включая те, которые мы не рассматривали в этом разделе. На основе анализа и экспериментов установите, какой из этих методов наиболее эффективен (дайте критерий!) при различных диапазонах значений N. Задача, по существу, заключается в определении, какой метод сортировки является лучшим для «малых» N, лучшим для «средних» N и лучшим для «больших» N. Уделите особое внимание вопросу о том, где кончается диапазон малых значений и начинается диапазон средних значений. Вы можете счесть необходимым рассмотреть более трех диапазонов. Воспользуйтесь генераторами случайных чисел. 5.2. Поиск Теперь обратимся к исследованию некоторых основных проблем, относящихся к поиску информации на структурах данных. Как и в разд. 5.1, посвященном сортировке, будем предполагать, что вся информация хранится в записях, которые можно идентифицировать значениями ключей, т. е. записи Ri соответствует значение ключа, обозначаемое Ki. Предположим, что в файле расположены случайным образом N записей в виде линейного массива. Очевидным методом поиска за- данной записи будет последовательный просмотр ключей, как это делалось в алгоритме МАХ в гл. 1. Если найден нужный ключ, поиск оканчивается успешно; в противном случае будут просмотрены все ключи, а поиск окажется безуспешным. Если все возможные порядки расположения ключей равновероятны, то такой алгоритм требует 0{N) основных операций как в худшем, так и в среднем случаях (см. упр. 5.2.4). Время поиска можно заметно уменьшить, если предварительно упорядочить файл по ключам. Эта предварительная работа имеет смысл, если файл достаточно велик и к нему обращаются часто. Далее будем предполагать, что у нас есть N записей, уже упорядоченных по ключам так, что Ki<K2<- -Kn- Пусть дан ключ К и нужно найти соответствующую запись в файле (успешный поиск) или установить ее отсутствие в файле (безуспешный поиск). Предположим, что мы обратились к середине файла и обнаружили там ключ Ki- Сравним К и Ki- Если K=Ki, то нужная запись найдена. Если K<Ki, то ключ К должен находиться в части файла, предшествующей Ki (если запись с ключом К вообще существует). Аналогично, если Ki<.K, то дальнейший поиск следует вести в части файла, следующей за Ki- Если повторять эту процедуру проверки ключа Ki из середины непросмотренной части файла, тогда каждое безуспешное сравнение К с Ki будет исключать из рассмотрения приблизительно половину непросмотренной части. Блок-схема этой продедуры, известной под названием двоичный поиск, приведена на рис. 5.2.1. Algorithm BSEARCH {Binary search - двоичный поиск) поиска записи с ключом К в файле с N2 записями, ключи которых упорядочены по возрастанию Ki<ZKz- .<Км- Шсз 0. [Инициализация] Set FIRST--1; LAST--A. (FIRST и LAST - указатели первого и последнего ключей в еще не просмотренной части файла.) Шаг 1. [Основной цикл] While LAST>FIRST do through шаг 4 od. Шаг 2. [Получение центрального ключа] Set / -f- [ (FIRST-Ь +LAST)/2J . (Kf-ключ, расположенный в середине или слева от середины еще не просмотренной части файла.) Шаг 3. [Проверка на успешное завершение] И К=Кг then PRINT «Успешное окончание, ключ равен К/»; and STOP fi. Шаг 4. [Сравнение] If K<Ki then set LAST 7-1 else set FIRST Ч-/+1 fi. Шаг 5. [Безуспешный поиск] PRINT «безуспешно»; and STOP. Алгоритм BSEARCH используется для отыскания К=42 на рис. 5.2.2. Метод двоичного поиска можно также применить для того, чтобы представить упорядоченный файл в виде двоичного дерева. Значение Начало I Инициализация FIRST*-1 LAST*- N 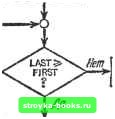 Результат: безуспешно" ->(ошчание Получение централбного ключа К,- 
Рис. 5.2.1. Блок-схема двоичного поиска, ключа, найденное при первом выполнении шага 2 (/С(8)=53), является корнем дерева. Интервалы ключей слева (1, 7) и справа (9, 16) от этого значения помещаются на стек. Верхний интервал снимается со стека и с помощью шага 2 в нем отыскивается средний элемент (или элемент слева от середины). Этот ключ (/С(4)=33) становится следующим после корня элементом влево, если его значение меньше значения корня, и следующим вправо в противном случае. Подынтервалы этого интервала справа и слева от вновь добавленного ключа 1(1. 3), (5, 7)] помещакугся теперь на стек. Эта процедура повторяется До тех пор, пока стек не окажется пустым. На рис. 5.2.3 показано Двоичное дерево, которое было бы построено для 16 упорядоченных ключей с рис. 5.2.2. [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36] [37] [38] [39] [40] [41] [42] [43] [44] [45] [46] [47] [48] [49] [50] [51] [52] [53] [54] [55] [56] [57] [58] [59] [60] [61] [62] [63] [64] [65] [66] [67] [68] [69] [70] [71] [72] [73] [74] [75] [ 76 ] [77] [78] [79] [80] [81] [82] [83] [84] [85] [86] [87] [88] [89] [90] [91] [92] [93] [94] [95] [96] [97] [98] [99] [100] [101] [102] [103] [104] [105] [106] [107] [108] [109] [110] [111] [112] [113] [114] [115] [116] [117] 0.0014 |