
|
|
|
Главная Полное построение алгоритма [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [ 18 ] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36] [37] [38] [39] [40] [41] [42] [43] [44] [45] [46] [47] [48] [49] [50] [51] [52] [53] [54] [55] [56] [57] [58] [59] [60] [61] [62] [63] [64] [65] [66] [67] [68] [69] [70] [71] [72] [73] [74] [75] [76] [77] [78] [79] [80] [81] [82] [83] [84] [85] [86] [87] [88] [89] [90] [91] [92] [93] [94] [95] [96] [97] [98] [99] [100] [101] [102] [103] [104] [105] [106] [107] [108] [109] [110] [111] [112] [113] [114] [115] [116] [117] в массивах. В эту обработку входит инициализация, поиск, хранение и модификация. Недостатки массивов не так очевидны. Лучше всего массивы годятся для данных, значения которых не изменяются, порядок которых (важен он или не важен) также не изменяется. Если порядок элементов в массиве подвергается изменению, то каждый раз, когда порядок меняется, перестановка элементов требует очень много времени. esioo исключить 3 ИСКЛЮЧИТЬ 8 9 10 ADAMS BUCHANAN GRANT HARRISON JACKSON KENNEDY LINCOLN ROOSEVELT TRUMAN WASHINGTON 1 2 3 ДОБАВИТЬ Б 6 7 8 S CS100 ADAMS BUCHANAN HARRISON JACKSON JEFFERSON KENNEDY LINCOLN TRUMAN WASHINGTON Рис. 2.3.1. Переорганизация линейного списка. Рассмотрим, например, Л-элементный массив CSIOO(A), в котором содержатся лексикографически упорядоченные имена студентов, слушающих в данный момент курс программирования CS100 (рис. 2.3.1, а). Если студенты ГРАНТ и РУЗВЕЛЬТ перестают посещать курс, а новый студент ДЖЕФФЕРСОН добавляется, то нам бы хотелось получить новый список слушателей, приведенный на рис. 2.3.1, б. Подумайте о трудности и стоимости написания и выполнения программы, которая смогла бы перестроить массив CS100 в соответствии с этими изменениями. С другой стороны, связанный список представляет собой структуру данных, которая требует дополнительной памяти, но позволяет легко вносить такие изменения. Связанные списки На рис. 2.3.2, а массив CS100 преобразован из одномерного в двумерный массив CS100L. В столбце 1 массива CS100L по-прежнему содержатся фамилии студентов, зачисленных на курс CS100, хотя, как явствует из рис 2 3.2, б, теперь уже не требуется, чтобы зги фамилии были упорядочены по алфавиту. В столбце 2 массива CS100L содержатся неотрицательные целые числа, называемые связями или указателями, значениями которых являются номера строк массива, содержащих фамилию следующего студента (в алфавитном порядке) в текущем
CSlOOt 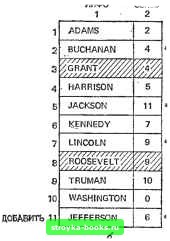 Рис. 2.3.2. Переорганизация связанного списка. списке. Звездочкой (*) мы отметили те указатели, значения которых изменились в связи с удалением фамилий GRANT и ROOSEVELT и добавлением JEFFERSON. Заметим, что на рис. 2.3.2, б: ADAMS указывает на BUCHANAN [CS100L (1, 2)=2 и CS100L(2, 1)=BUCHANAN]. BUCHANAN указывает на HARRISON [CS100L(2, 2)=4 и CS100L(4, 1)=HARRIS0N]. JACKSON указывает на JEFFERSON. JEFFERSON указывает на KENNEDY и т. д. Массив CS100L(/, J) размера Nx2 работает как линейный связанный список. Линейный связанный список - это конечный набор пар, каждая из которых состоит из информационной части INFO (ИНФО) и указующей части LINK (СВЯЗЬ). Каждая пара называется ячейкой. Если мы хотим расположить ячейки в порядке сц, сц, . . . . . . , Ci„, то СВЯЗЬ ({j)=tj+i для /=1, . . . , я-1, а СВЯЗЬ(1"„)=0 и указывает на конец списка. На рис. 2.3.3, а приведена стандартная диаграмма линейного связанного списка; на рис. 2.3.3, б приведена диаграмма связанного списка с рис. 2.3.2, б. Заметим, что GRANT и ROOSEVELT отсутствуют в списке на рис. 2.3.3, б, хотя они присутствуют на рис. 2.3.2, б как заштрихованные элементы. При реализации связанных списков участвует переменная FIRST (ПЕРВЫЙ) или HEAD (ГОЛОВА), значение которой есть адрес первой ячейки списка (рис. 2.3.3, а). Как было указано выше, одно из главных преимуществ связанных списков заключается в том, что можно легко удалять и добавлять элементы списка. Далее мы приводим два алгоритма, которые можно использовать при вьшолнении модификаций, требуемых для преобразования рис. 2.3.2, а в 2.3.2, б. Cn-I ПЕРВЫЙ инФо связь тФо связь инФо связь инФО связь тФо связь
JACKSON РяВ 5 JEFFERSON РяЭ 11 KENNEDY РяО 6 LINCOLN TRUMAN РяЭ? РяЭЭ
Ряв 10 Рис. 2.3.3. Диаграммы линейных связанных списков. Первый алгоритм будет удалять заданный элемент из связанного списка. Этот процесс иллюстрируется на рис. 2.3.4, где мы ищем ячейку сь у которой ИНФ0(1)=ТРИ, передвигая указатели PREV и PTR до тех пор, пока такая ячейка не найдена. Затем мы заменяем значение СВЯЗЬ в ячейке, на которую указывает PREV, на значение СВЯЗЬ в ячейке, на которую указывает PTR. Далее следуют блок-схема (рис. 2.3.5), формальное описание и реализация (рис. 2.3.6) этого алгоритма. Algorithm DELETE (УДАЛЕНИЕ). Удаляется ячейка Си у которой INFO(t)=VALUE из связанного списка, первая ячейка которого задается переменной FIRST. Шаг 1. [Выбор первой ячейки] Set PTR FIRST; PREV х- 0. Шаг 2. [Ячейка пуста?] While PTR=70 do шаг 3 od. Шаг 3. [Это она?] If INFO (PTR)=VALUE then [Это первая ячейка?] if PREV=0 then [удалить спереди] set FIRSTS LINK(PRT); and STOP [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [ 18 ] [19] [20] [21] [22] [23] [24] [25] [26] [27] [28] [29] [30] [31] [32] [33] [34] [35] [36] [37] [38] [39] [40] [41] [42] [43] [44] [45] [46] [47] [48] [49] [50] [51] [52] [53] [54] [55] [56] [57] [58] [59] [60] [61] [62] [63] [64] [65] [66] [67] [68] [69] [70] [71] [72] [73] [74] [75] [76] [77] [78] [79] [80] [81] [82] [83] [84] [85] [86] [87] [88] [89] [90] [91] [92] [93] [94] [95] [96] [97] [98] [99] [100] [101] [102] [103] [104] [105] [106] [107] [108] [109] [110] [111] [112] [113] [114] [115] [116] [117] 0.0018 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||